Lessons Learned Building an Open-Source Answer Engine
I built an open-source answer engine called Farfalle. Given a query, it searches the web and uses either local or cloud LLMs to generate answers grounded in the search results.
It's a clone of Perplexity but it's open-source, can be self-hosted, and supports local LLMs.
There's a lot of interesting things I learned about building an answer engine, and I'm writing some of my thoughts here.
Search Engines Do Most of the Work
Building a good RAG (Retrieval-Augmented Generation) system is not easy. With your own search index, you need to worry about retrieval, re-ranking, query speed etc.
But search engines do almost all of that for you. The top results are already ranked, relevant, and you can't do much better than what they give you.
You might think getting the relevant context to feed into the LLM is difficult. I've seen other answer engines with complicated implementations:
- Perform a search
- Retrieve the relevant links
- Scrape all the pages
- Embed and index the information into a vector database
- Perform similarity search between the query and the indexed information to get the relevant context
- Feed the relevant context into the LLM to generate an answer
Suprisingly, you don't need to do this because:
- It's really slow
- Search engines are really good. They already provide excerpts relevant to your query, and this is all the context you need to generate an answer.
Because the snippets are relevant to the query, there's no need to scrape the page content for most questions.
We can optimize the search results for LLM answers with a re-ranking step, but we only need the page title, snippet, and url to do so. It seems like the search API I used, Tavily, does something like this.
For people who've wondered: "How is Perplexity so fast!?" (I have), this is how. I'm pretty confident that they only use the snippets provided by the search engine to generate their answers (apart from PDFs and specfic sites they've indexed).
I combined this technique with Groq's inference engine, and it can answer questions nearly instantly.
Small vs Large models
Farfalle has models of varying sizes: 7b quantized local models, 70b llama3, and larger models: gpt-3.5-turbo and gpt-4o.
I noticed that the smaller the model, the more it struggles with remembering unique instructions. This might seem obvious, but the difference is significant.
See the full answer generation prompt here: prompts.py.
"""
[Instructions on answering questions...]
DO NOT include a reference section, DO NOT include URLs.
DO NOT repeat the question.
[More instructions....]
Question: {my_query}
Answer (without repeating the question): \
"""The prompt clearly states: do not include a reference section and do not repeat the question (twice!).
Large Models - gpt4-o has no problem with this, it consistently follows these instructions.
Medium Models - llama3-70b sometimes makes a reference section, but doesn't explicitly call it "References". It also sometimes repeats the question.
Small Models - The 7b parameter models pretty consistently do the opposite of these instructions! They start their responses by repeating the question, and finish them with an explicit reference section. Sometimes the quantized models can't even follow the citation format.
My best guesses for why this happens:
- Less parameters = less capacity to remember unique instructions
- Smaller models = less sophisticated attention mechanisms = worse ability to prioritize important parts of the prompt.
An interesting observation I made is that Llama3 models repeat the query by default, but OpenAI's models do not. This might suggest that differences in the instruction tuning datasets might be a factor.
Random Observations
It seems like Perplexity has begun to build and use their own search index for some queries. The query "what happened to ilya" returns results that I couldn't find on any other search engine. However, these results are not great.
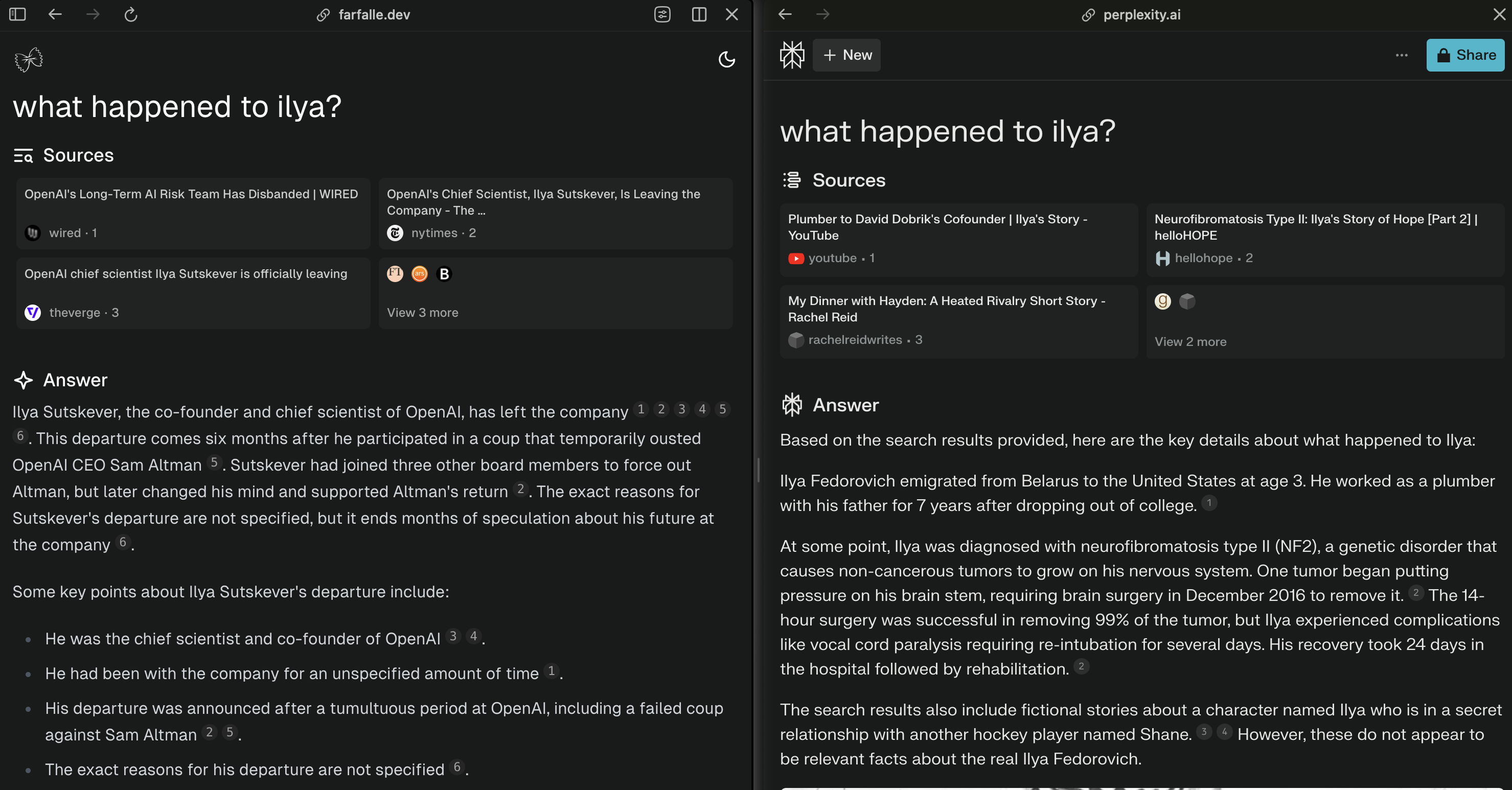
Anyone searching "what happened to ilya" right now (May 2024) is referring to Ilya Sutskever and OpenAI. The larger search engines realize that, but Perplexity's does not yet.
If this is the case, I think it's super cool that Perplexity is building their own search index. Search is extremely hard and Perplexity is one of the few companies that I think stands a chance at disrupting it.
Conclusion
I'm a big fan of Perplexity. It's one of the few tools AI tools that I use frequently, and I'm excited to see where it goes.
I built Farfalle for fun and to figure out how Perplexity works. Check out the source code and live demo!
I hope you found this interesting, and I'm happy to hear any feedback!